On-Demand High-Performance GPUs für Training-Workloads
Voll gemanagte KI-Infrastruktur – sofort per API verfügbar. Verfügbar im Sommer 2026.
Voll gemanagte KI-Infrastruktur – sofort per API verfügbar. Verfügbar im Sommer 2026.




Von grossskaligem Training bis zu schneller Inference liefert unsere Virtual AI Cloud die zentrale Infrastruktur für Ihren gesamten KI-Lifecycle in einer souveränen Hochleistungsumgebung.
| Polarise. |
|---|
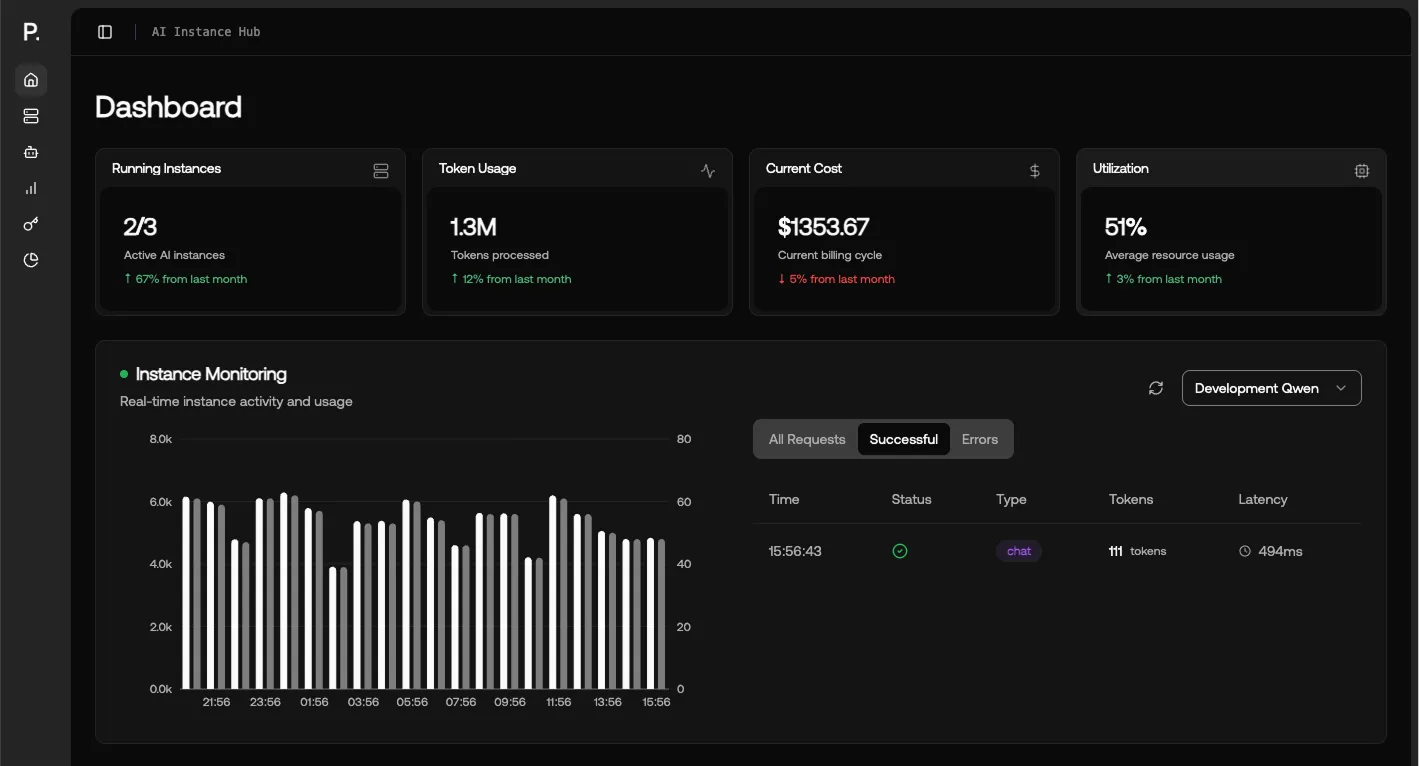
✓ Eine zentrale Control Plane für jede KI-Workload - von Training bis Inference, über Cloud und On-Prem hinweg. |
✓ Trainieren Sie anspruchsvolle Modelle auf tausenden NVIDIA GPUs mit ultraniedriger Latenz für maximale Performance. |
✓ Starten Sie leistungsstarke NVIDIA GPU-Instanzen in Sekunden - ideal für Prototyping, ML-Experimente und skalierbare Inference. |
✓ Vereinfachen Sie Ihren ML-Lebenszyklus von Experiment-Tracking bis Deployment mit einem voll gemanagten MLflow-Service. |
✓ Verarbeiten Sie grosse Datenmengen schnell mit einer optimierten, voll gemanagten Spark-Umgebung für Daten- und ML-Pipelines. |
✓ Deployen Sie ein reiches Oekosystem aus MLOps-Tools und Open-Source-Software per One-Click-Kubernetes-Apps. |
Core bietet zentrale Services für Ihre KI-Infrastruktur - inklusive Compute, Storage und Container-Management.
Betreiben Sie GPU-VMs und Cluster in unserer robusten Cloud-Umgebung.
Speichern, teilen und verwalten Sie grosse Mengen unstrukturierter Daten einfach und sicher.
Verwalten Sie Ihre Compute-Cluster mit unserem gemanagten Kubernetes-Service.
Speichern und verwalten Sie Ihre Container-Images sicher.
Speichern Sie strukturierte Daten in einer zuverlaessigen, objekt-relationalen Datenbank.
NVIDIA B300-GPU-Instanzen, sofort und in Europa als Bare-Metal-GPU oder GPUaaS verfügbar. Trainieren, fine-tunen und betreiben Sie anspruchsvolle KI-Workloads mit Hyperscaler-Leistung und der Kontrolle einer dedizierten Infrastruktur – bei Polarise kein Problem.
Der HGX B300 verdoppelt die Attention-Performance für Transformer- und Long-Context-Workloads gegenüber der Vorgängergeneration und beschleunigt moderne Reasoning- und Retrieval-Modelle.
Mit 2,1 TB Hochgeschwindigkeits-GPU-Speicher unterstützt der HGX B300 größere Modelle, längere Sequenzen und höhere Concurrency, ohne an Speichergrenzen zu stoßen.
Hochbandbreitige Interconnects bieten 1,6 TB/s Netzwerk-Bandbreite pro Node und ermöglichen nahtlose Skalierung über Multi-Node-Cluster für verteiltes Training und Inferenz.
Die Spezifikationen vergleichen den NVIDIA HGX B300 NVL16 mit dem HGX B200.
Höchste Performance mit dem NVIDIA GB300 Grace Blackwell Ultra Superchip: 72 Blackwell Ultra GPUs und 36 Grace CPUs mit bis zu 40 TB schnellem Speicher und 130 TB/s NVLink-Bandbreite.
Mehr Speicher ermöglicht grössere Batches und maximalen Durchsatz. NVIDIA Blackwell Ultra GPUs bieten 1,5x mehr HBM3e-Speicher.
Volle Beschleuniger-Leistung braucht nahtlose Kommunikation zwischen allen GPUs.
Das E/A-Modul der ConnectX-8 SuperNIC hostet zwei ConnectX-8 Geraete – 800 Gb/s Netzwerk pro GPU.
Angaben zur Performance beziehen sich auf den GB300 NVL72 Superchip mit 72 NVIDIA Blackwell Ultra GPUs und 36 NVIDIA Grace CPUs mit bis zu 40 TB schnellem Speicher und 130 TB/s NVLink-Bandbreite.
Polarise hat den Status als NVIDIA Preferred Partner erreicht und ist als offizieller NVIDIA Cloud Service Provider (CSP) gelistet. Diese Auszeichnung ist ausgewählten Partnern vorbehalten, die grosse Cluster in enger Abstimmung mit NVIDIA auf Basis einer getesteten Referenzarchitektur betreiben.
Erweitern Sie Ihre private Infrastruktur per dedizierter physischer Cross-Connects direkt in unsere KI-Cloud in großen europäischen Rechenzentren.
Minimieren Sie Netzverzögerungen für Echtzeit-Inference und latenzkritische Anwendungen durch direkte Anbindung im Rechenzentrum.
Umgehen Sie das öffentliche Internet mit einer dedizierten physischen Verbindung und schützen Sie Daten im Transit.
Planbare, leistungsstarke Verbindungen für grosse Datentransfers, Modelltraining und volumenstarke Inference.
Vereinen Sie On-Prem- oder Colocation-Ressourcen mit unserer gemanagten KI-Plattform.
Kontrollieren Sie Datenpfade und Compliance-Anforderungen mit Konnektivität über wichtige europäische Datacenter-Hubs.
Nutzen Sie aktuelle NVIDIA-Server und Cluster, optimiert für anspruchsvolle KI-Workloads und on-demand skalierbar.
Antworten auf Häufige Fragen zur Polarise Cloud Plattform.

