Souveräne KI für Europa
Physische KI-Infrastruktur 'Made in Germany' ganz einfach über unsere Cloud-Plattform abrufbar - konform mit europäischer Regulierung.
Physische KI-Infrastruktur 'Made in Germany' ganz einfach über unsere Cloud-Plattform abrufbar - konform mit europäischer Regulierung.
Polarise bietet sichere, skalierbare und souveräne Kl-Infrastruktur von Colocation bis Cloud - aus Europa, für Europa.

CEO





Von reiner Infrastruktur bis zum Model-as-a-Service: Polarise liefert die gesamte Wertschöpfungskette aus einer Hand. Damit Teams sich wieder darauf konzentrieren können, echten Mehrwert zu schaffen.
Fine-Tuning, Inferenz und API-Zugriff
Zugang zu den aktuellsten Open-Source-Modellen für unterschiedlichste Modell Anwendungen, z.B. Text- und Bildgenerierung. Wunschmodell fehlt? Wir fügen es hinzu!
Dedizierte, sichere KI-Cloud-Cluster.
Ein dediziertes GPU-Cluster für Ihre KI-Workloads mit neuester NVIDIA-Blackwell-Architektur. Ideal für Produktion und große Projekte – Abrechnung pro GPU und Stunde.
Gemeinsam besprechen wir Ihre genauen Anforderungen in einem persönlichen Gespräch. Zusammen finden wir die passende Lösung für Ihr Projekt.
Polarise ist eine modulare, verteilte Infrastrukturplattform für die KI-Ära. Sie bietet einen flexiblen, skalierbaren Ansatz für Compute, Storage und Netzwerk - optimiert für moderne KI-Workloads.
| Traditionell | Polarise. |
|---|---|
| Zentralisierte Megastrukturen | ✓ Modulare, regionsnahe Rechenzentrumsstrategie |
| Ueberdimensioniert und starr | ✓ Bereitstellen, was Sie brauchen, wo Sie es brauchen |
| Lange Zyklen, veraltete Hardware | ✓ Kontinuierlich aufgeruestete, KI-optimierte Compute (GPU-first) |
| Vendor-Lock-in, komplexe Vertraege | ✓ Offene APIs, transparente Abrechnung, einfache Integration |
| US-Anbieter mit CLOUD-Act-Risiko | ✓ Vollstaendig europäisch, DSGVO-nativ, ohne Extraterritorialität |
| Generischer Compute, nicht KI-spezifisch | ✓ Auf ML-Workloads zugeschnitten: Vector DBs, RAG, Model Serving |
| Keine feingranulare Kontrolle | ✓ Volle Datenresidenz und Souveränität pro Region |
| Flache Zonen, schwache Edge-Kapazität | ✓ Edge-ready AI Pods bis 1 MW, in 30 Tagen deploybar |
Wir bieten keine „EU-Regionen“ an – wir sind ein europäisches Unternehmen. Unsere gesamte Organisation, Infrastruktur und der Betrieb unterliegen vollständig EU-Recht und ausschließlich europäischer Gerichtsbarkeit.
Daten und Metadaten unterliegen nicht ausserhalb der EU geltenden Ueberwachungsgesetzen oder grenzueberschreitenden Offenlegungen.
Sie bestimmen, wo Workloads laufen. Daten bleiben in Europa – immer.
Infrastruktur und Schnittstellen sind auf Datenschutz, Transparenz und Rechteverwaltung ausgelegt.
Nachvollziehbare Kontrollen, Zugriffsrichtlinien und Audit-Trails. Ihre Modelle, Ihre Regeln.
Von Storage und Compute bis MLOps und Observability – alle Dienste unter derselben rechtlichen und technischen Souveränität.
Grosse Modellauswahl, nahtlose Integration und Werkzeuge mit Fokus auf Entwickler.
Einheitliche API für Text, Vision und multimodale Modelle – einfache Integration in jeden Stack.
Vom Prototyp bis in die Produktion.
Top-Modelle für LLM, Vision, Bildgenerierung und mehr – neue Modelle kommen monatlich dazu.
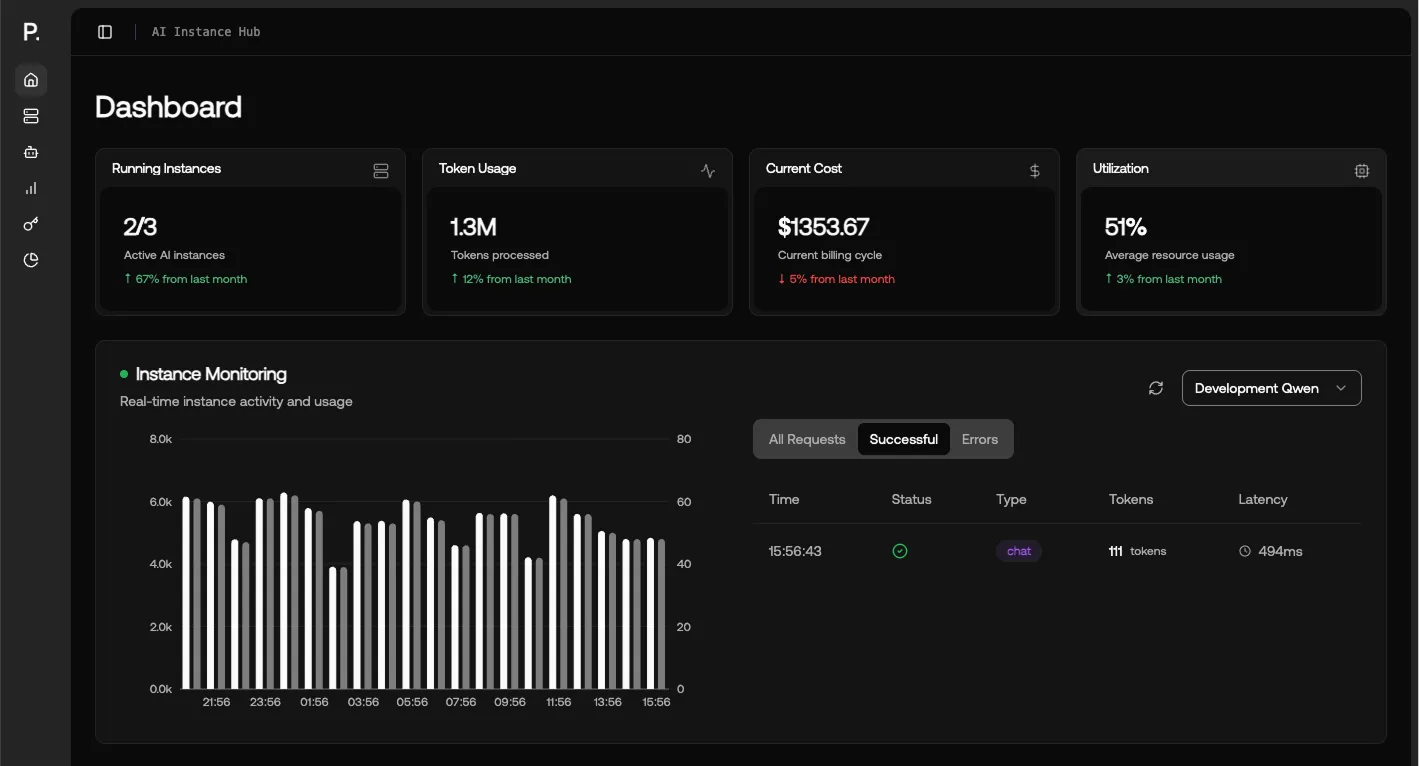
Alles für echte KI-Workloads – von Compute bis MLOps, integriert und skalierbar.
Hochperformante GPU-Cluster, skalierbarer Storage und sicheres Kubernetes für Production.
Experiment-Tracking, Model Registry und eingebaute Unterstützung für RAG und Vektorsuche.
CLI, GUI und API mit SDKs für Python und Go sowie feingranulare Zugriffskontrolle.
NVIDIA B300-GPU-Instanzen, sofort und in Europa als Bare-Metal-GPU oder GPUaaS verfügbar. Trainieren, fine-tunen und betreiben Sie anspruchsvolle KI-Workloads mit Hyperscaler-Leistung und der Kontrolle einer dedizierten Infrastruktur – bei Polarise kein Problem.
Der HGX B300 verdoppelt die Attention-Performance für Transformer- und Long-Context-Workloads gegenüber der Vorgängergeneration und beschleunigt moderne Reasoning- und Retrieval-Modelle.
Mit 2,1 TB Hochgeschwindigkeits-GPU-Speicher unterstützt der HGX B300 größere Modelle, längere Sequenzen und höhere Concurrency, ohne an Speichergrenzen zu stoßen.
Hochbandbreitige Interconnects bieten 1,6 TB/s Netzwerk-Bandbreite pro Node und ermöglichen nahtlose Skalierung über Multi-Node-Cluster für verteiltes Training und Inferenz.
Die Spezifikationen vergleichen den NVIDIA HGX B300 NVL16 mit dem HGX B200.
Höchste Performance mit dem NVIDIA GB300 Grace Blackwell Ultra Superchip: 72 Blackwell Ultra GPUs und 36 Grace CPUs mit bis zu 40 TB schnellem Speicher und 130 TB/s NVLink-Bandbreite.
Mehr Speicher ermöglicht grössere Batches und maximalen Durchsatz. NVIDIA Blackwell Ultra GPUs bieten 1,5x mehr HBM3e-Speicher.
Volle Beschleuniger-Leistung braucht nahtlose Kommunikation zwischen allen GPUs.
Das E/A-Modul der ConnectX-8 SuperNIC hostet zwei ConnectX-8 Geraete – 800 Gb/s Netzwerk pro GPU.
Angaben zur Performance beziehen sich auf den GB300 NVL72 Superchip mit 72 NVIDIA Blackwell Ultra GPUs und 36 NVIDIA Grace CPUs mit bis zu 40 TB schnellem Speicher und 130 TB/s NVLink-Bandbreite.
| Datum | Event | Ort | |
|---|---|---|---|
House of Communication, Friedenstraße 24, 81671 Munich | |||
Le Carrousel du Louvre, Paris, France | |||
Maritim proArte Hotel, Berlin | |||
Berlin, Deutschland |