Sovereign AI for Europe
Sovereign, physical AI infrastructure 'Made in Germany' easily accessible through our cloud computing platform - compliant with European regulation.
Sovereign, physical AI infrastructure 'Made in Germany' easily accessible through our cloud computing platform - compliant with European regulation.
Polarise delivers scalable, sovereign AI infrastructure - built in Europe, deployable anywhere, and optimized for Europe’s next-generation AI leaders.

CEO





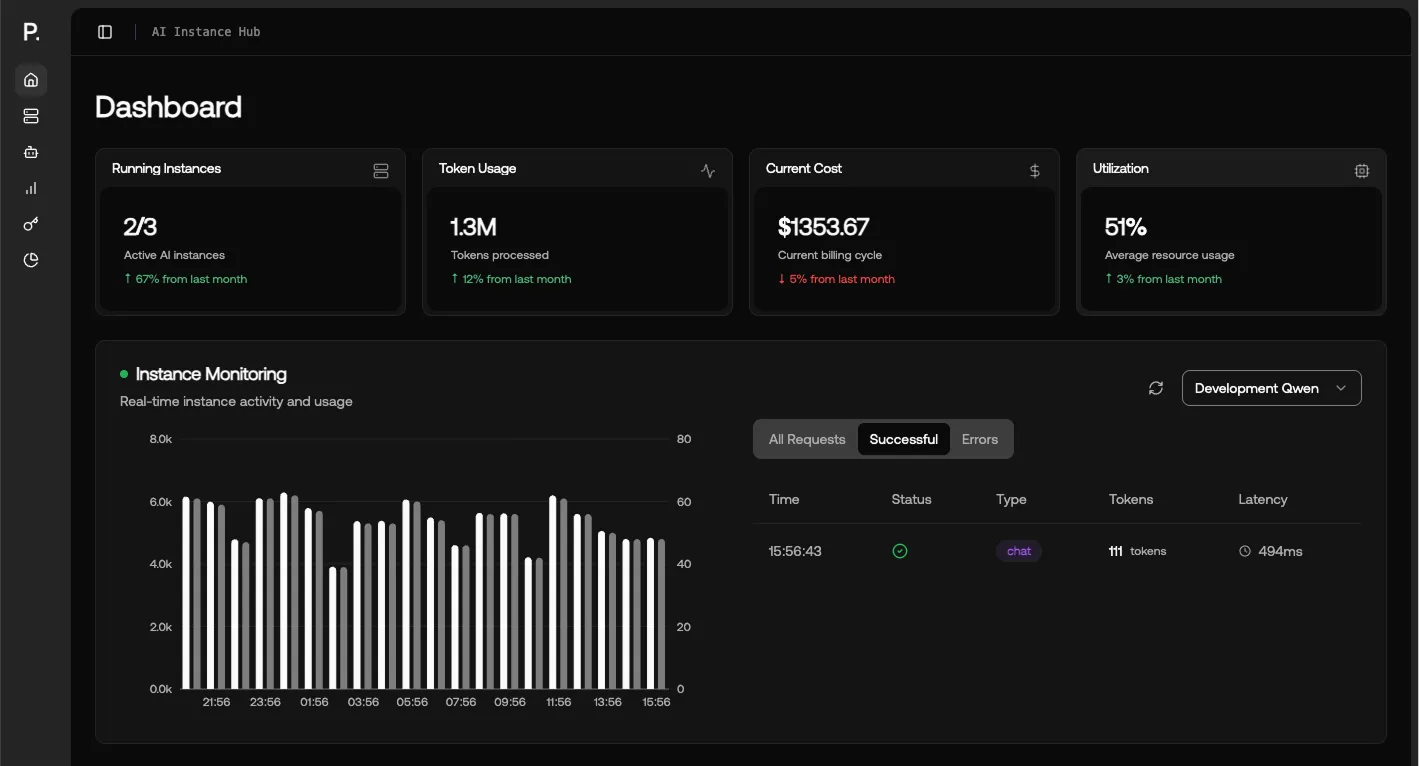
From raw compute to managed services, Polarise delivers the full set of tools and infrastructure to accelerate your AI journey.
Fine-tuning, inference and API access
Access state-of-the-art AI models across multiple categories - from text generation to image creation, speech synthesis, and more. If you don't see the model you need, reach out to us and we'll add it.
Dedicated, secure AI cloud clusters.
Get a dedicated cluster of GPUs for your AI workloads with the latest NVIDIA Blackwell architecture. Perfect for production workloads and large-scale AI projects - pay per GPU per hour.
Let's discuss your specific requirements in a personal conversation. I'll help you find the perfect AI Infrastructure solution for your organization.
Polarise is a modular, distributed infrastructure platform designed for the AI era. It offers a flexible and scalable approach to compute, storage, and networking, optimized for modern AI workloads.
| Traditional | Polarise. |
|---|---|
| Centralized megastructures | ✓ Modular, region-first datacenter strategy |
| Overprovisioned and inflexible | ✓ Deploy what you need, where you need it |
| Long refresh cycles, aging hardware | ✓ Continuously upgraded AI-optimized compute (GPU-first) |
| Vendor lock-in, complex contracts | ✓ Open APIs, transparent billing, easy integration |
| US-based providers with CLOUD Act exposure | ✓ Fully European, GDPR-native, no extra-jurisdiction risk |
| Generic compute, not AI-specific | ✓ Tailored for ML workloads: vector DBs, RAG, model serving |
| No fine-grained control over data locality | ✓ Full data residency & sovereignty per region |
| Flat availability zones, poor edge capacity | ✓ Edge-ready AI Pods up to 1MW, deployable in 30 days |
We don't offer 'EU regions' — we are a European company. Our infrastructure, operations, and legal entities are entirely governed by EU law and subject only to European jurisdiction.
Data and metadata are never subject to non-EU surveillance laws or cross-border subpoenas.
Choose exactly where your workloads run. Data stays in-region — always.
Infrastructure and interfaces are built to support privacy, transparency, and rights management from the start.
Verifiable controls, access policies, and audit trails. Your models, your rules.
From storage and compute to MLOps and observability — all services operate under the same legal and technical sovereignty.
Access a wide variety of models, seamless integration, and developer-centric tools.
Unified API for text, vision, and multimodal models. Simple integration for any stack.
Scale from prototype to production.
Access top-tier models for LLM, vision, image generation, and more. New models added monthly.
Everything you need for real AI workloads – from compute to MLOps, fully integrated and ready to scale.
High-performance GPU clusters, scalable storage, and secure Kubernetes for production workloads.
Experiment tracking, model registry, and built-in support for RAG and vector search.
CLI, GUI, and API access with SDKs for Python and Go, plus fine-grained access control.
Sovereign high-performance NVIDIA HGX B300 GPU instances in Europe, available as bare metal or GPUaaS. Train, fine-tune and deploy frontier AI workloads with the performance of a hyperscaler and the control of dedicated infrastructure.
The HGX B300 doubles attention performance for transformer and long-context workloads compared to the previous generation, accelerating modern reasoning and retrieval models.
With 2.1 TB of high-speed GPU memory, the HGX B300 supports larger models, longer sequences and higher concurrency without running into memory bottlenecks.
High-bandwidth interconnects deliver 1.6 TB/s of networking bandwidth per node, enabling seamless scaling across multi-node clusters for distributed training and inference.
Specifications compare the NVIDIA HGX B300 NVL16 to the HGX B200.
Experience groundbreaking performance with the NVIDIA GB300 Grace Blackwell Ultra Superchip, featuring 72 Blackwell Ultra GPUs and 36 Grace CPUs with up to 40 TB of fast memory and 130 TB/s NVLink bandwidth.
Larger memory capacity allows for larger batch sizing and maximum throughput performance. NVIDIA Blackwell Ultra GPU's offer 1.5x larger HBM3e memory.
Unlocking the full potential of accelerated computing requires seamless communication between every GPU.
The NVIDIA ConnectX-8 SuperNIC's input/output (IO) module hosts two ConnectX-8 devices, providing 800 gigabits per second (Gb/s) of network connectivity for each GPU.
Performance is based on the GB300 NVL72 Superchip, featuring 72 NVIDIA Blackwell Ultra GPUs and 36 NVIDIA Grace CPUs with up to 40 TB fast memory and 130 TB/s NVLink bandwidth.
| Date | Event | Location | |
|---|---|---|---|
Maritim proArte Hotel, Berlin | |||
Berlin, Germany |